In today’s era of real-time collaboration, audio is the lifeline of digital communication. From virtual meetings and voice-activated assistants to real-time transcription engines and AI-driven support bots, the need to process audio both quickly and accurately is more critical than ever.
In applications where users expect near-instantaneous interaction, even a minor delay can disrupt the user experience.
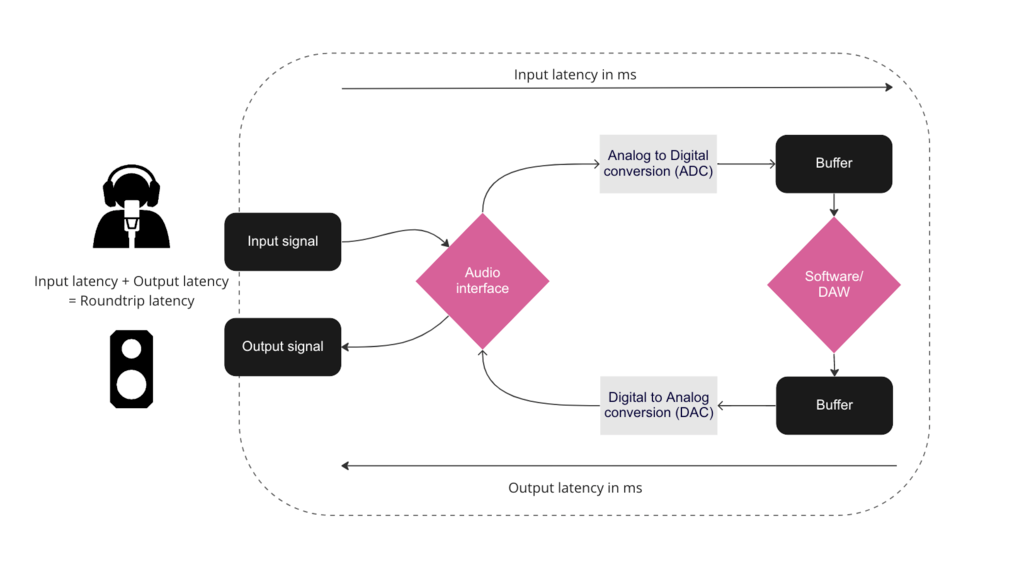
Low-latency audio processing in Python has become a foundational requirement for developers building intelligent meeting tools. Latency above 300 milliseconds introduces perceptible lag, interrupting the natural rhythm of conversation and diminishing the real-time feel.
Fortunately, Python’s mature ecosystem of libraries—combined with infrastructure APIs like MeetStream.ai—makes it possible to build fast, scalable, and platform-agnostic audio pipelines that power intelligent communication tools.
This post explores how developers can leverage Python and MeetStream to create robust low-latency audio systems for modern meeting applications.
Why Low-Latency Audio Processing Matters in Meeting Bots
In the context of voice applications, low latency generally refers to end-to-end delays of under 300 milliseconds—covering the entire chain from audio capture, streaming, signal analysis, to response generation.
For applications like live transcription, voice-controlled assistants, and emotion-aware interfaces, even a 500ms delay can break user immersion and slow down real-time collaboration.
With low-latency processing, bots can immediately detect voice triggers like “follow up,” or “let’s schedule,” or deliver instant pronunciation feedback during language coaching. Real-time sentiment analysis can help generate live emotional heatmaps for meetings, revealing stress levels, engagement, or dissatisfaction.
However, achieving such responsiveness involves a trade-off: more complex models and longer audio contexts tend to be more accurate but introduce additional delay.
Developers must strike a delicate balance between processing speed and analytical depth, often favoring lightweight models and frame-based analysis that can operate on audio slices of 20–100 milliseconds without sacrificing insight.
Tools and Libraries for Audio Processing in Python
Python is uniquely positioned to support real-time audio applications thanks to its blend of flexibility, speed, and extensive library support.
- Audio I/O & Streaming:
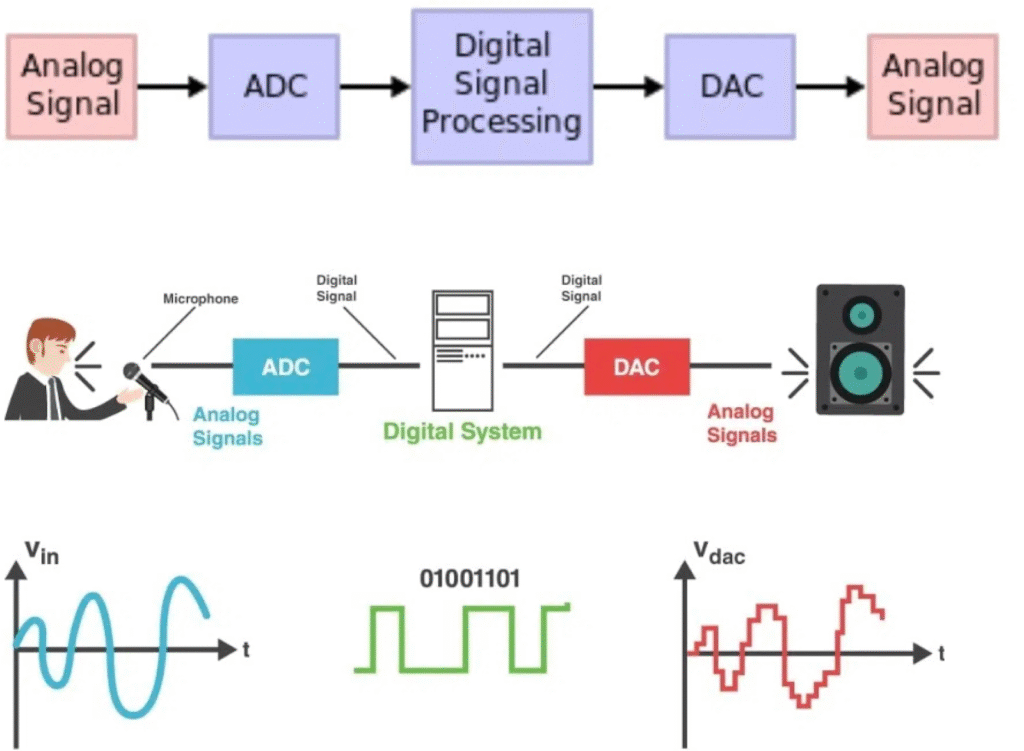
Libraries like pyaudio, sounddevice, and soundfile enable real-time microphone input and audio playback with fine-grained control over sampling rate, buffer sizes, and audio formats—key factors for achieving sub-300ms latency. - Signal Processing:
numpy and scipy offer efficient tools for low-level operations like Fourier transforms, filtering, windowing, and resampling. These libraries allow precise manipulation of waveform data and feature extraction in real time. - Voice Activity Detection (VAD):
Webrtcvad is a lightweight, production-ready library that detects speech segments at the frame level (10–30ms), making it ideal for reducing noise and filtering silence before deeper analysis. - Audio Feature Extraction & Modeling:
librosa, torchaudio, and speechrecognition are widely used for computing features like MFCCs, spectrograms, and chroma vectors, essential for downstream tasks like speech-to-text, keyword spotting, and emotion recognition. - Concurrency & Parallelism:
For real-time responsiveness, using asyncio, concurrent. futures, or multiprocessing, allows you to process audio chunks concurrently, ensuring audio input capture and model inference run in parallel without blocking.
To maintain a real-time experience, most pipelines process audio chunks between 10–100ms, depending on the task complexity.
Choosing the right window size and leveraging non-blocking, event-driven architecture is key to maintaining low-latency performance.
Streaming Audio with MeetStream API for Real-Time Processing
One of the biggest hurdles in real-time audio apps is acquiring consistent, low-latency audio streams from diverse conferencing platforms like Zoom, Microsoft Teams, and Google Meet—all of which have different APIs and restrictions. This is where MeetStream.ai transforms the developer experience.
MeetStream acts as a unified audio ingestion layer, capturing live meeting audio via WebRTC, RTMP, or platform-specific integrations, and delivering it through WebSocket or HTTP streaming APIs.
This API-first approach removes the complexity of writing custom logic for each platform.
Here’s how it works:
- Audio is delivered in chunked formats, typically 20–100ms segments, encoded in raw PCM or base64.
- These chunks are streamed in real time to your application using Python’s WebSocket or HTTP client libraries.
- Python-based bots can then process the chunks using VAD, sentiment models, or ASR (automatic speech recognition) systems.
For instance, a meeting assistant could:
- Receive 40ms of audio.
- Detect voice activity and check for specific phrases using a keyword spotting model.
- Analyze sentiment using a fine-tuned transformer like distilBERT or wav2vec2.
- Instantly push updates to a real-time dashboard or meeting transcript.
Because MeetStream handles audio ingestion, routing, and standardization, developers can focus solely on processing logic, ensuring faster development and seamless platform support.
Building a Low-Latency Audio Pipeline in Python – Step-by-Step
Here’s a step-by-step breakdown of how to build an end-to-end low-latency audio processing system using Python and MeetStream:
- Connect to MeetStream’s WebSocket API
Use websockets or aiohttp to establish a persistent connection to MeetStream. Configure authentication and subscribe to the meeting’s audio stream. - Receive Audio Chunks
The API will deliver chunked audio, often 16-bit PCM at 16kHz—ideal for speech tasks. Parse and decode the base64 data into numpy arrays for processing. - Apply Voice Activity Detection (VAD)
Use webrtcvad to analyze whether the audio contains speech. Drop silent frames or background noise to conserve processing resources. - Extract Features
Apply librosa or torchaudio to extract features such as:
- MFCCs for speech recognition.
- Spectrograms for deep learning inputs.
- Zero-crossing rate or pitch for emotion or prosody detection.
- MFCCs for speech recognition.
- Run ML Inference
Depending on your use case, run the chunk through:
- A speech-to-text model (e.g., Whisper, Vosk, wav2vec2).
- A sentiment analysis model trained on emotional tone.
- A custom command recognizer for voice assistants.
- A speech-to-text model (e.g., Whisper, Vosk, wav2vec2).
- Emit Real-Time Insights
Results (transcripts, commands, scores) can be sent to a dashboard, browser client, or chatbot via sockets, webhooks, or REST endpoints. - Use Async or Background Queues
Implement asyncio or tools like Celery to avoid blocking I/O and to maintain responsive performance across all components.
This pipeline supports sophisticated features like:
- Live subtitles
- Voice-command recognition
- Real-time meeting highlights
- Speaker tone/emotion tracking
Performance Optimization Tips for Real-Time Audio Systems
Optimizing a real-time audio system is as much about architecture as it is about code. Here are critical performance tips:
- Keep processing under chunk duration: For a 300ms latency budget, each 100ms chunk should be processed in ≤200ms, leaving room for transmission overhead.
- Use asynchronous processing:
asyncio ensures that your chunk reader doesn’t wait for inference to complete before grabbing the next audio piece. - Warm-start heavy models:
Load deep learning models once during app boot and keep them in memory to reduce cold start delays. - Leverage batching:
Accumulate several small chunks and batch them through the model in one forward pass—ideal for GPU-backed inference. - Monitor pipeline metrics:
Use monitoring tools to track:
- Queue lengths
- Processing time per chunk
- Memory/CPU utilization
- Dropped frame counts
- Queue lengths
- Adapt to load dynamically:
Under heavy load, reduce model complexity or switch to fallback logic (e.g., basic keyword spotting instead of full ASR). - Use efficient formats:
16kHz, 16-bit PCM provides an excellent trade-off between quality, size, and inference speed—the standard for most ASR and emotion models.
By thoughtfully combining concurrency, load balancing, and hardware acceleration, developers can maintain stable sub-300ms latency even during demanding workloads.
Conclusion
Low-latency audio processing in Python is a foundational capability for building the next generation of intelligent meeting and collaboration tools.
Whether you’re enabling live transcription, powering a real-time voice assistant, or analyzing emotional tone in conversations, the ability to process audio in milliseconds unlocks compelling user experiences.
With Python’s robust audio stack and machine learning ecosystem, developers can prototype and scale real-time solutions quickly.
However, tools like MeetStream.ai are what truly enable these applications to operate at scale—handling the platform-specific audio ingestion, stream normalization, delivery logistics, and even streaming audio back into the meeting, so developers can focus on analytics, not infrastructure.
By combining Python’s analytical flexibility with MeetStream’s real-time streaming APIs, teams can create responsive, AI-powered applications that listen, understand, and act—faster than ever before.
Related Guides
- Meeting Bot APIs and SDKs: Complete Developer Guide [2026]
- What Is a Meeting Bot Developer Platform? Complete Guide [2026]
- AI Meeting Agents vs Traditional Transcription Tools
- How to Record Google Meet: Complete Guide [2026]
- How to Record Microsoft Teams Meeting
- Top 7 Use Cases for AI Meeting Bots [2026]
What is real-time audio processing for meeting bots?
Real-time audio processing refers to capturing, analyzing, and responding to live audio streams with end-to-end latency under 300 milliseconds. For meeting bots, this enables features like live transcription, voice command recognition, sentiment analysis, and speaker identification during virtual meetings on Zoom, Google Meet, and Microsoft Teams.
Which Python libraries are best for low-latency audio processing?
Key Python libraries include pyaudio and sounddevice for audio I/O, numpy and scipy for signal processing, webrtcvad for voice activity detection, librosa and torchaudio for feature extraction, and asyncio for non-blocking concurrent processing. These libraries enable sub-300ms processing pipelines when configured correctly.
How does MeetStream API help with real-time audio streaming?
MeetStream acts as a unified audio ingestion layer that captures live meeting audio from Zoom, Google Meet, and Microsoft Teams via WebRTC or RTMP, then delivers chunked audio (20-100ms segments) through WebSocket or HTTP streaming APIs. This eliminates the need to build platform-specific audio capture logic for each conferencing platform.
What latency is acceptable for meeting bot audio processing?
For real-time meeting applications, end-to-end latency should stay under 300 milliseconds. Latency above 500ms creates perceptible lag that disrupts conversation flow. Most production pipelines process audio in 20-100ms chunks, leaving headroom for model inference and network transmission within the 300ms budget.
Can I use Python for production-grade real-time audio pipelines?
Yes. Python’s ecosystem of optimized C-backed libraries (numpy, scipy, torchaudio) combined with asyncio for concurrency makes it viable for production real-time audio. For GPU-accelerated inference, frameworks like PyTorch and TensorFlow integrate seamlessly. MeetStream’s API handles the heavy lifting of cross-platform audio capture and delivery.
How do I optimize audio processing performance for meeting bots?
Key optimizations include: keeping per-chunk processing time under the chunk duration, using asyncio for non-blocking I/O, warm-starting ML models at boot time, batching chunks for GPU inference, using 16kHz 16-bit PCM format, and monitoring queue lengths and dropped frames. Dynamic load adaptation—falling back to simpler models under heavy load—also helps maintain consistent latency.