

In recent years, the field of computer vision has undergone a rapid transformation, particularly in real-time object detection.
From security surveillance and autonomous vehicles to gesture recognition and intelligent video conferencing, the demand for fast, accurate, and scalable detection models has grown exponentially.
While convolutional neural networks (CNNs) such as YOLO and Faster R-CNN have long dominated this space, the rise of transformer-based models has ushered in a new era of innovation.
A standout among these models is DETR (Detection Transformer), which replaced complex, multi-stage pipelines with a streamlined end-to-end transformer architecture.
However, despite its groundbreaking approach, DETR struggled with slow convergence, high computational demands, and underperformance in detecting small objects—issues that limited its real-world deployment in low-latency applications.
Enter RF-DETR (Receptive Field DETR), a next-generation object detector that retains DETR’s conceptual simplicity while overcoming its most pressing limitations.
In this article, we’ll explore how RF-DETR works, what makes it ideal for real-time environments, and why it could be the catalyst for practical adoption of vision transformers in production systems.
A Quick Recap: What is DETR and Where It Falls Short
To appreciate RF-DETR, it’s essential to understand its predecessor, DETR, developed by Facebook AI Research (FAIR).
DETR was among the first models to treat object detection as a set prediction problem, utilizing a pure transformer architecture rather than relying on region proposal networks, anchor boxes, or non-maximum suppression (NMS).
This approach allowed DETR to process images more holistically, making it well-suited for dense scenes, overlapping objects, and multi-class detection.
DETR’s end-to-end trainability removed the need for hand-engineered components, producing more interpretable and consistent predictions.
However, DETR’s real-world usability was hindered by:
- Extremely slow training, often requiring 500+ epochs on datasets like COCO
- High computational complexity due to global attention mechanisms
- Poor performance on small or fine-grained objects
- Infeasibility for edge devices or real-time inference scenarios
These challenges limited DETR’s adoption in environments that demand low-latency and resource-efficient solutions.
What is RF-DETR and How It Enhances DETR
RF-DETR (Receptive Field DETR) is a transformer-based object detection model purpose-built for real-time performance.
It builds on DETR’s foundation but introduces multi-scale receptive field attention, allowing the model to dynamically attend to features at varied spatial resolutions.
The key innovations of RF-DETR include:
- Adaptive Receptive Fields: By incorporating multi-scale attention, RF-DETR can capture both local detail (critical for small objects) and global context (important for large scenes).
- Faster Convergence: Improved feature-query interactions and more efficient positional encodings reduce the number of training epochs needed.
- Lightweight Architecture: RF-DETR maintains DETR’s clean design but introduces low-overhead modifications, making it suitable for edge GPUs, mobile platforms, and IoT devices.
- Real-Time Inference: Unlike DETR, RF-DETR offers latency performance that supports video analytics, robot vision, and interactive systems.
This hybrid of speed, accuracy, and architectural simplicity makes RF-DETR a compelling choice for developers looking to deploy vision transformers in production.
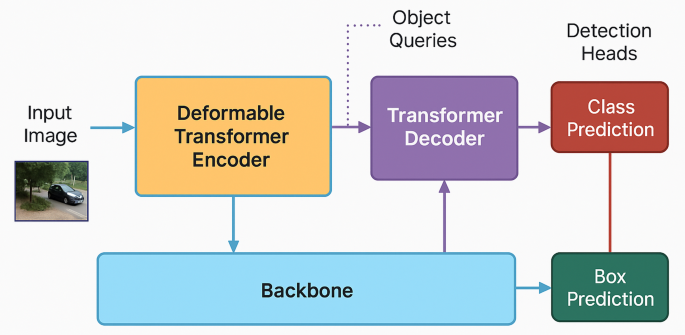
How RF-DETR Works – A Deeper Look
At a high level, RF-DETR follows a similar pipeline to DETR:
- A feature extraction backbone (e.g., ResNet or Swin Transformer) encodes input images.
- An encoder-decoder transformer processes these features.
- The model predicts a fixed number of bounding boxes and class labels.
The primary innovation lies in its receptive field-aware attention layers. Traditional DETR applies attention uniformly, which is computationally expensive and suboptimal for detecting objects of varying sizes. RF-DETR introduces hierarchical receptive fields, allowing attention heads to focus selectively on different regions and scales.
Additionally, RF-DETR benefits from:
- Optimized query embeddings that enhance localization accuracy
- Streamlined positional encodings for better spatial awareness
- Efficient token interactions that accelerate learning and inference
Importantly, RF-DETR avoids anchor boxes, proposal generators, and NMS, preserving the elegance and end-to-end nature of DETR while dramatically improving usability.
Real-Time Applications of RF-DETR (and How MeetStream Could Leverage It)
One of RF-DETR’s most valuable traits is its ability to perform low-latency detection without sacrificing accuracy. This makes it ideal for use cases across industries:
1. Surveillance & Smart Security
RF-DETR enables real-time anomaly detection, person tracking, and activity recognition in smart cameras and edge-based security systems.
2. Autonomous Vehicles & Drones
With its low latency and robust scene understanding, RF-DETR can support pedestrian detection, traffic sign recognition, and obstacle avoidance in autonomous systems, including UAVs and robotics.
3. Smart Meetings & Video Intelligence
A particularly exciting application lies in meeting intelligence platforms like MeetStream.ai. Already equipped with speech recognition, transcription, and meeting summarization, MeetStream can integrate RF-DETR to:
- Detect participant gestures, facial expressions, and eye gaze
- Enable real-time speaker tracking and attention analysis
- Identify interactions with shared media (e.g., whiteboards, documents)
Because RF-DETR is lightweight and modular, it can run directly in the user’s browser or on local hardware, ensuring both privacy and performance—an ideal match for API-first platforms like MeetStream.
4. Logistics, AR, and Edge AI
From warehouse automation to augmented reality apps, RF-DETR offers a real-time object detection solution that scales across devices and environments without compromising efficiency.
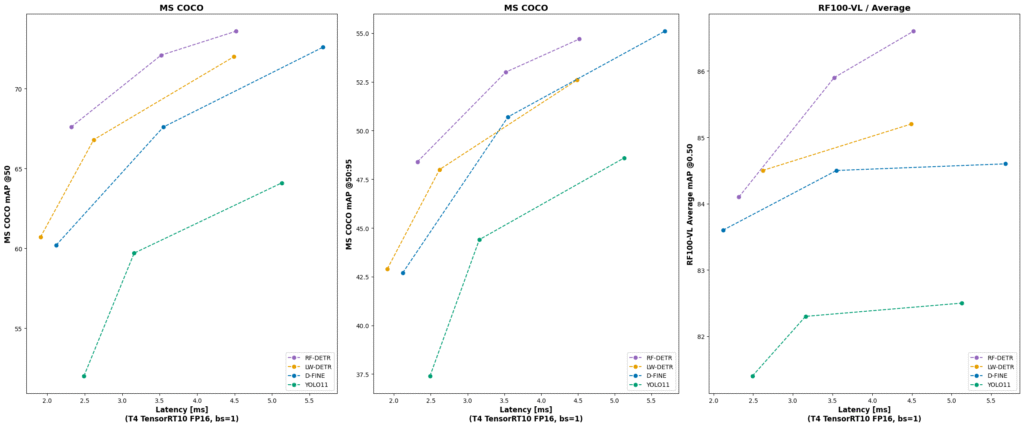
Comparing RF-DETR with YOLOv8, DETR, and RT-DETR
To better understand RF-DETR’s place in the ecosystem, it helps to benchmark it against leading models:
| Model | Speed | Accuracy | Architecture | Real-Time Suitability |
| YOLOv8 | ✅ Fast | ⚠️ Moderate | CNN-based | ✅ Excellent |
| DETR | ❌ Slow | ✅ High | Transformer-based | ❌ Limited |
| RT-DETR | ⚠️ Moderate | ✅ Strong | Optimized Transformer | ⚠️ Moderate |
| RF-DETR | ✅ Fast | ✅ High | Transformer with RFA | ✅ Excellent |
- YOLOv8 excels in real-time speed but often requires hand-tuned parameters and may miss fine-grained details.
- DETR is powerful for dense or cluttered scenes but is impractical for edge deployment.
- RT-DETR makes DETR faster but doesn’t fully resolve training inefficiency or small object detection.
- RF-DETR combines the scalability of transformers, the speed of CNNs, and accuracy across object scales, making it ideal for modern AI pipelines.
Conclusion
RF-DETR represents a major leap in the evolution of transformer-based object detection.
By addressing DETR’s core limitations—slow training, high latency, and inefficiency with small objects—RF-DETR enables smarter, faster, and more practical visual understanding for the real world.
Whether you’re developing AI-powered cameras, intelligent robotics, or multi-modal meeting tools, RF-DETR delivers the performance needed to operate in real-time and resource-constrained environments.
For platforms like MeetStream.ai, which already offer cutting-edge audio and transcript analysis, RF-DETR adds a new layer of visual intelligence.
From gesture tracking to speaker identification and scene-based content segmentation, the potential is vast.
As demand for real-time, AI-powered computer vision grows, RF-DETR stands out as a model that brings both innovation and implementation within reach.


